
【游戏开发】游戏中的平面阴影怎么做
光和影是渲染领域最核心的两个需求,伴随着实时图形学的发展数十年,学界和工业界的相关研究也层出不穷,要综述这个话题实在是个大活儿,所以我还是从Shadow Map和Ray-Traced Shadow出发,围绕这两种时下最流行的方案对相关算法做一个梳理。

从最简单的阴影开始
阴影是表示空间位置关系的重要线索,抛开其视觉质量本身不谈,有和没有阴影能够提供的视觉信息量是完全不同的。哪怕只是在角色脚下渲染一个半透明圆盘,也能够很大程度上改善游戏的3D体验,很多早期的游戏里确实就是这么干的。
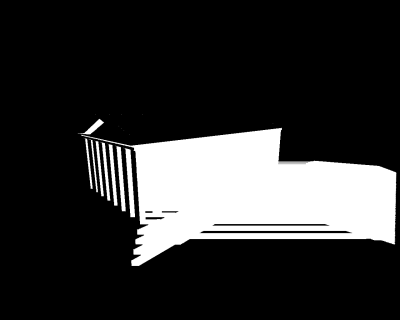
相比小圆盘更复杂一点的阴影技术叫做平面阴影(Planar Shadow),它基于一个简单的观察:物体在平面上的投影还是能够清晰地保持自身的轮廓,就好像模型被压扁在平面上了。
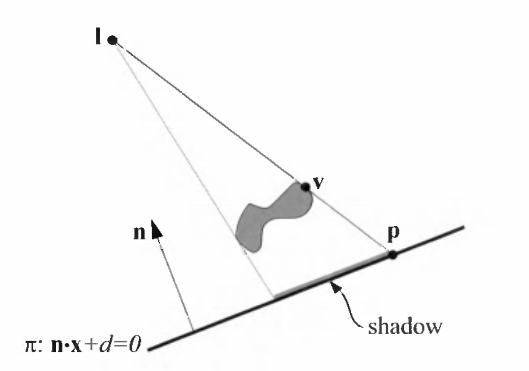

(1)先绘制平面,再关闭深度测试和写入进行平面阴影的绘制,最后再打开深度的测试和写入进行模型的正常绘制。
(2)在平面投影矩阵中,稍稍减小(或者增大,取决于法线的方向)一点d的值,让实际的投影平面位于模型平面上方。
第二个问题是半透明叠加。早期游戏在绘制阴影的时候,为了模拟全局照明的贡献,通常不会把阴影绘制为纯黑,而是带一定半透明的黑色。于是当三角面被压扁在投影平面上时,会产生重叠,这时如果开启半透明混合,不论使用什么样的叠加模式最后都会出现错误的半透明效果,因为实际上我们只希望平面上最多覆盖一个像素的半透明阴影。解决方法是首先绘制下方的模型平面,并向Stencil Buffer写入一个指定值(比如1),然后开启模板测试,比较函数设为EQUAL,测试通过后模板值 1[2],这样如果某个点已经绘制过一次半透明阴影,则相同位置就不会再绘制第二次。

平面阴影技术至今也还活跃在很多手游中,对于机能有限的平台仍然是很好的选择。它不存在阴影走样的问题,绘制性能也很高,同时也有一些缺陷,最严重的当然是影子只能投射在平面上,对于曲面上的投影就无能为力了;其次,如果光源恰好位于被投影物体和平面之间,理论上是不产生投影的,但是实际上它会在平面上投射出错误的阴影来;此外,平面投影算法无法模拟软阴影。
Shadow Volume
阴影体(Shadow Volume)[3]也是个比较古老的技术,虽然现在已经鲜有游戏使用,但是算法本身还是相当精巧。Shadow Volume名气最大的应用当属传奇大佬John Camack开发的《DOOM3》,算法思路见下图:
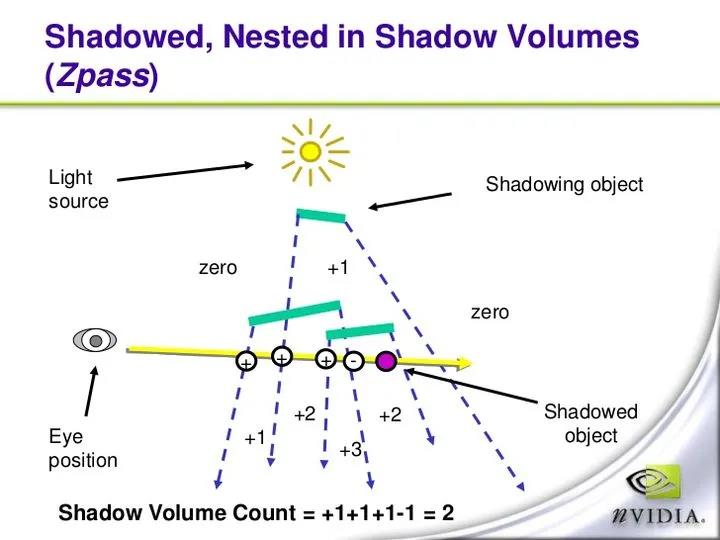

这个算法解释起来稍微有点复杂。首先,我们从光源位置出发,针对阴影遮挡体的每个三角面生成一系列半开的棱台,这些棱台被我们称之为阴影体(Shadow Volume),所有位于阴影体内部的点,都会被遮挡而看不到光源,也就是需要绘制阴影的位置。那么如何判断一个点是否位于阴影体内部呢?这正是算法的关键所在:假设我们从摄像机向屏幕上任一点发射一条线段,当线段和阴影体正面相交时,则表示它进入了一个阴影体,当线段和阴影体背面相交时,则表示它离开了一个阴影体,于是,我们每进入一个阴影体,就让交点数 1,反之离开一个阴影体,就让交点数-1,如果最终所有交点数(Shadow Volume Count)为0,则表示当前点位于阴影体之外,若交点数大于0,则表示当前点位于阴影体内。于是判断一个点是否位于阴影体内的问题就变成了判断Shadow Volume Count是否大于0。
具体实现:
(1)打开ZWrite/ZTest,关闭Stencil Write/Test,绘制一遍场景(只绘制非投影光源的贡献)
(2)关闭ZWrite,ZTest保持Less Equal,打开Stencil Write,将其设置为 1,Stencil Test设为总是通过,绘制投影光源的阴影体正面
(3)将Stencil Write设置为-1,绘制投影光源的阴影体背面
(4)将ZTest设置为Equal,关闭Stencil Write,Stencil Test设置为Equal,再次绘制场景中Stencil Value为0的区域(叠加模式为ADD,绘制非阴影区域,且本次只绘制投影光源的贡献)
上述算法基于一个假设:摄像机本身是位于阴影体外的,但实际情况往往并非如此。于是John Carmark在原始算法的基础上进行了改进,提出了ZFail算法。不同于ZPass的算法,这次线段发射的起点位于距离摄像机无限远处(我们可以肯定这个点一定是位于阴影体外的),然后我们每次遇到阴影体背面,就让Stencil Value 1,遇到阴影体正面,就让Stencil Value-1,其他设定均不变。
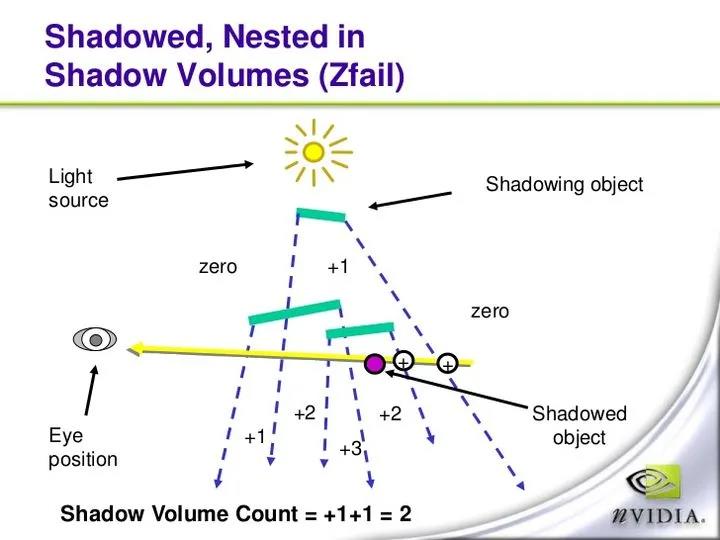
Shadow Volume的算法能够生成精确的硬阴影,但也有一些明显的缺点,比如难以实现软阴影效果,此外场景的多遍绘制加上阴影体的生成和绘制,使得算法对场景几何复杂度非常敏感。
Shadow Map
Shadow Map[4]是目前主流的阴影生成算法,这主要得益于它算法直观,并且能够充分利用现代硬件的光栅化能力。
标准的Shadow Map算法思路很简单,也是很多人入门图形学的基础算法之一:对于指定光源来说,场景中某个点是否被其照亮,取决于从光源的视角看去,这个点是否可见。假设该点可见,则表示没有遮挡,反之则表示该点处于阴影中。于是,算法被分成了四步:


从光源视角生成Shadow Map

将光源投影空间的深度映射到屏幕空间
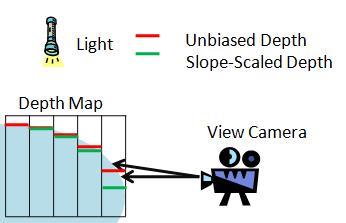
深度比较,确定阴影区域
由于光栅化导致的精度误差,通常直接比较深度会产生些许误差,产生所谓的“Shadow Acne”,通常的解决方案是在比较前给加上一个固定偏移,但是若偏移选取过大,又会产生所谓的“Peter-Panning”的问题,一个自适应偏移的方案,是基于斜率去计算当前深度要加的偏移(Slope Scale Depth Bias)。


由于相机和光源视角不同,从光源视角光栅化后的每个像素投影到屏幕空间后,对应的区域大小也不相同,所以往往会出现距离相机较近位置的Shadow Map精度不够,而距离相机较远位置的Shadow Map精度又过高的问题,于是就会出现阴影边缘的明显锯齿。
缓解这个问题的方法是把视锥沿着Z轴切分成多段,每段单独计算出一个光源坐标空间内的紧凑AABB,然后基于这个AABB生成多张Shadow Map,也就是所谓的级联式阴影(Cascaded Shadow Map)[5]。在进行深度查询时,首先根据当前像素在相机空间中的Z值确定其位于哪个分段中,然后找到对应分段的Shadow Map和投影矩阵。
在实际操作中,通常会选择3~4级分段,划分位置通常是指数划分和均匀划分的结果进行插值后得到。鉴于划分是基于视锥的,所以较远处的Shadow Map可以预先计算好[6],或者每隔几帧才更新一次,以此提高渲染效率。

相比标准Shadow Map,级联式Shadow Map的像素利用率提高了
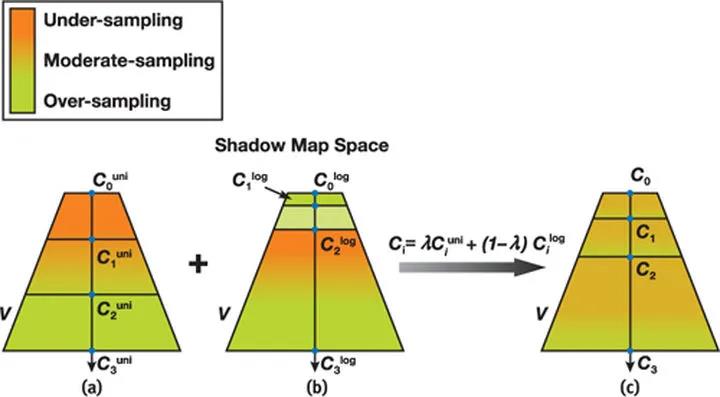
视锥划分算法
提高Shadow Map像素利用率的另一个方案是设法获得更加紧凑的视锥包围盒。由于相机在场景中始终处于变化状态,因此整个屏幕空间中可见像素的包围盒也在变化,且这个包围盒往往要比相机默认的视椎体紧凑许多,假设我们能够通过场景的ZBuffer去统计得到这个包围盒,再结合CSM去做场景划分,就可以最大限度的避免Shadow Map中像素的浪费,这就是Sample Distribution Shadow Map(SDSM)[7]的核心思想。

基于PSSM划分的场景层级分布

基于SDSM划分的场景层级分布

PSSM和SDSM视锥划分投影到光源空间后的面积


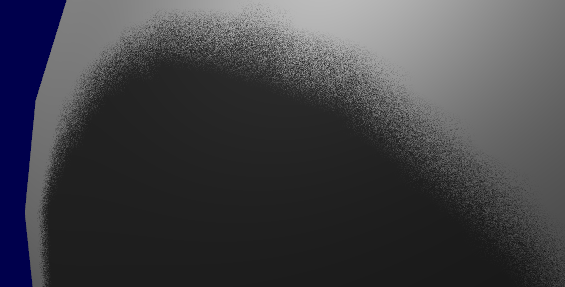
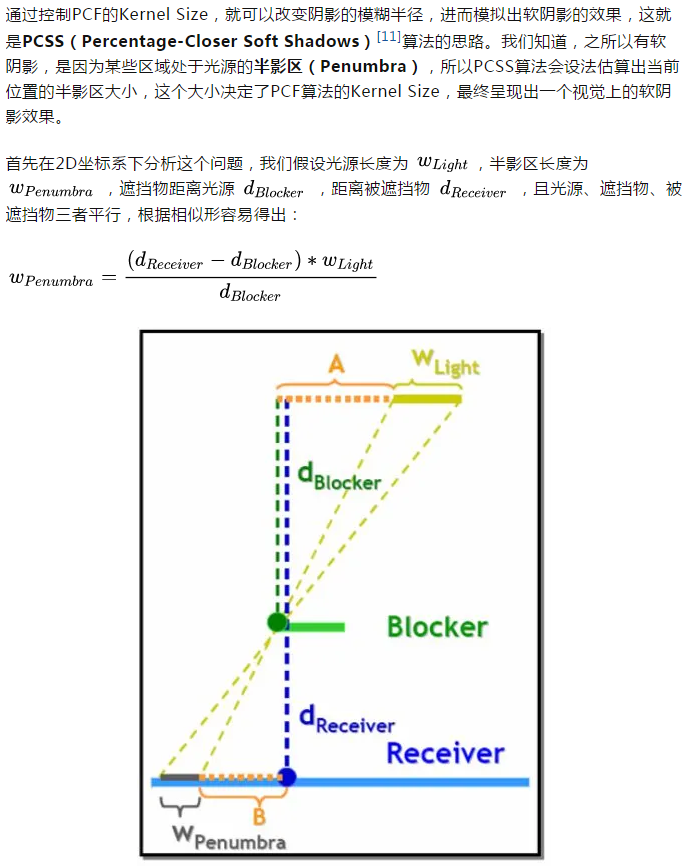
PCF方法看起来是美好的,但也存在一个致命的问题:它需要大量的采样,例如一个3x3的Kernel需要9次采样,5x5的Kernel则需要25次采样,随着采样半径增大,这个数字会迅速增加。这时候我们会自然地想到:不是可以把一个2D滤波拆分成两个独立的1D滤波再利用硬件的双线性采样来减少采样次数吗[12]?这个思路确实是对的,然而实际却不可行,因为我们的可见性判定函数是一个二值函数。进一步来说,

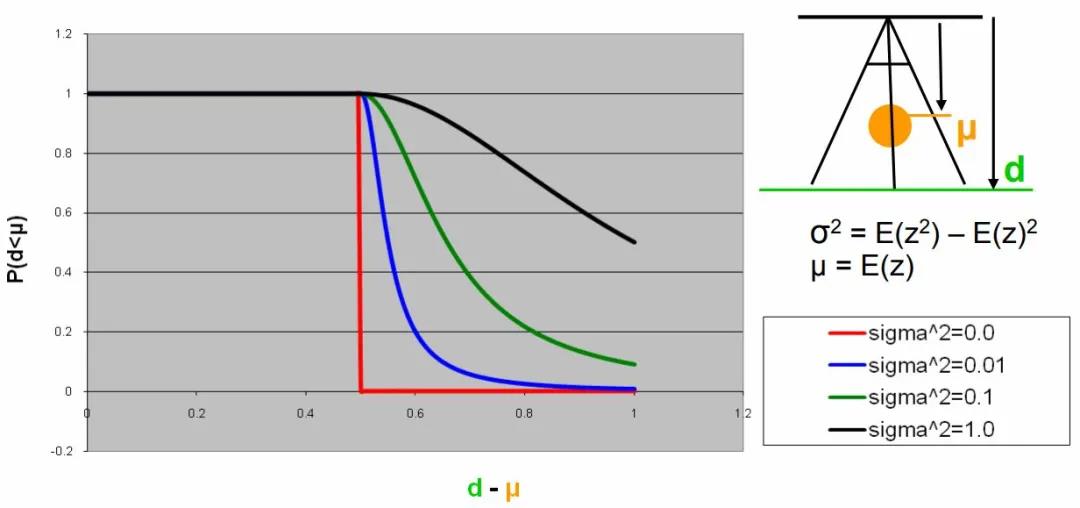
VSM的可见性判定函数

当然VSM也有一个显著的缺陷,观察切比雪夫不等式就可以发现,当Shadow Map某个区域内深度变化剧烈,导致 很大的时候,这个可见性估计就不再准确了,表现在视觉上,就是原本应该完全处于阴影的区域出现了漏光。

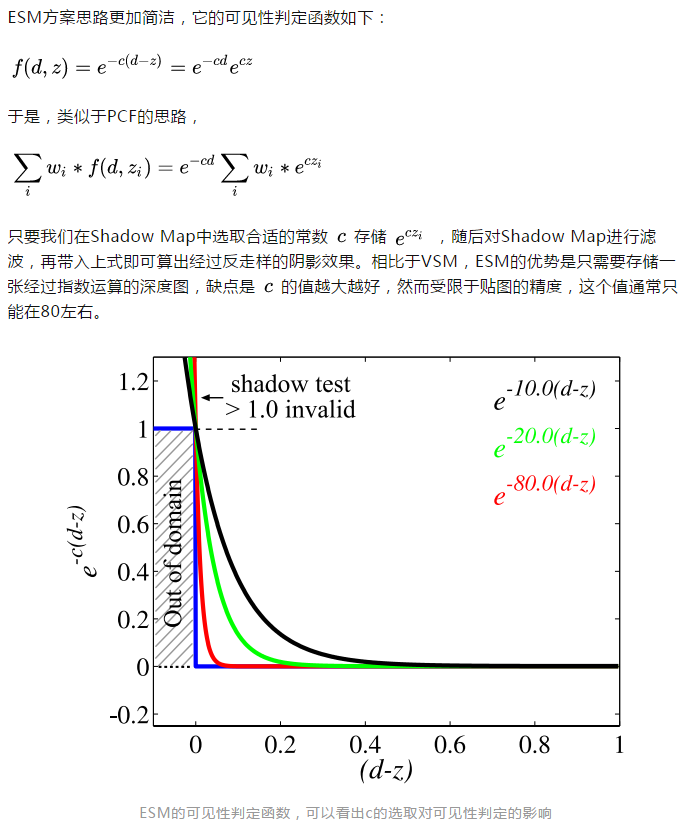
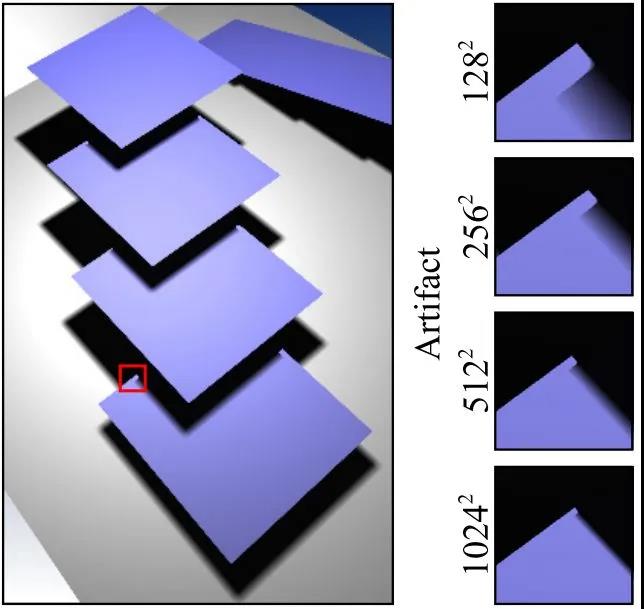
ESM由于贴图数值精度不足导致的错误
鉴于VSM和ESM各自的优缺点,也有人提出了两者结合的方案,即EVSM(Exponential Variance Shadow Maps)[15],这里不再详细展开。
以上都是通过设计一个能够预先滤波的可见性判定函数去改进Shadow Map的算法思路,类似的方案还有CSM(Convolution Shadow Maps)[16],也有一些综述类文档对比了它们各自的特性[17],这里我们不再赘述。
完结!!!
转载声明:本文来源于网络,不作任何商业用途
全部评论


暂无留言,赶紧抢占沙发
热门资讯
【游戏开发】UE4渲染引擎模块讲解

分享成长记录还能赚钱?!这么给力的活动赶快来参加吧!...

绘学霸订单服务协议V1.1.0

CGWANG王氏教育怎么样?

王座杯获奖采访集合

严禁刷票警告!!!

英国插画师 James Daw 拼贴感的插画

只有两人的团队研发了一款像素游戏《The Slormancer》Steam好...

《星际战甲》全新大版本4月1日上线,开启8周年活动...





